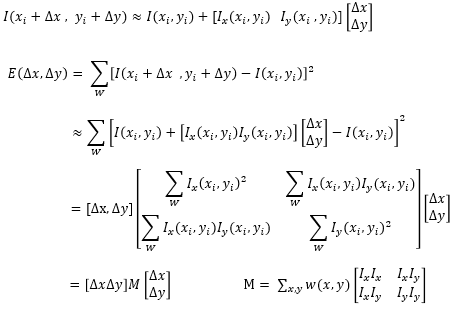OpenCV에서는 cornerHarris( ) 함수를 통해 쉽게 코너를 검출할 수 있도록 지원하고 있다.
하지만 상황에 따라 해당 함수를 사용하여 적용하기보단 나의 상황에 맞도록 코너검출의 과정을 수정하고 싶을 때가 있다. 이를 위해 opencv의 cornerHarris( ) 함수를 사용하지 않고 직접 구현하여 코너를 검출하는 과정에 대해 설명한다.
이를 위해 우선 어떻게 코너를 검출하는지 과정부터 살펴볼 필요가 있다.
기본적으로 2차원의 GrayScale 이미지는 아래와 같은 형태를 갖고 있다.
위의 그림에서 하나의 네모칸을 '픽셀'이라고 표현하며 GrayScale의 이미지는 0~255의 정수로 표현되는 픽셀값을 갖고 있다.
그럼 여기서 코너를 어떻게 정의할 수 있을까?
위의 그림에서 (a)는 그냥 아무런 특징이 나타나지 않는 면에 해당된다.
(b)의 경우 '엣지'라고 불리는 부분이며 말 그대로 모서리에 대한 부분을 나타내고 있다. 이러한 경우 x축의 방향으로는 픽셀값의 차이가 뚜렷하게 나타나지만(영상이 밝은곳에서 어두운곳으로 진행하다가 다시 밝은 부분이 나오게 된다.) y축 방향으로는 영상의 픽셀에 대한 변화가 나타나지 않게 된다. 다시 말해 분홍색 윈도우가 x축으로 이동하게 되면 변화가 발생하지만 y축으로 이동하면 변화가 발생하지 않는다. 이러한 부분을 엣지라고 정의한다.
(c)의 그림이 코너에 해당하는 부분으로 분홍색 윈도우를 x축, y축으로 이동시켜보면 어느 방향으로 이동시켜도 윈도우 내 영상에서 변화가 감지되게 된다. 이를 코너의 특징으로 볼 수 있다.
그럼 영상에서 코너를 왜 취득하는걸까? 코너가 갖는 의미는 무엇일까?
좌측의 그림과 같은 바다의 풍경이 담긴 사진이 있다고 보자.
우리는 A윈도우의 정보를 갖고 A가 원본 이미지의 어떤 위치를 나타내는지 알 수 있는가?
하늘은 모두 A와 유사하기에 "A가 정확히 여기이다!" 라고 말하기 어렵다.
B역시 바다의 수평선에 대한 정보(엣지)만 존재하므로 이 부분이 정확히 바다의 어떤 위치를 나타내는지는 알기 어렵다.
하지만 C는 어떤가. C의 위치는 원본 이미지에서 정확이 어떠한 부분인지를 나타낼 수 있는 정보를 보여주고 있다. 그리고 이는 '코너'정보를 갖고 있다. 이렇게 코너는 영상의 특징이 될 수 있는 정보를 담고있으므로 Feature Point(특징 점)으로 표현한다.
이를 수식으로 표현하면 다음과 같이 나타낼 수 있다.
내용을 보면 영상의 변화율 E는 영상 내 윈도우 w의 (x, y)에 대하여 이미지 I를 x축, y축으로 이동시켰을 때 나타나는 변화율의 크기를 통해 표현하고 있다.
위의 값이 크다면 영상의 x, y에 대한 차이가 크다는 것이고 이는 코너임을 나타낼 수 있다.
원래 CPU는 병렬처리가 안된다. 하지만 코어수를 늘림으로서 CPU의 역할을 분담하게 되고
이를 통해 병렬처리가 가능하게 된다. 이를 멀티스레드라 한다.
멀티프로세스는 하나의 CPU코어에서 다수의 프로세스를 짧게짧게 진행하는 것이다.
이를 통해 작업자는 여러개의 프로세스들이 동시에 진행되는 것 처럼 보이지만 사실은
짧게짧게 여러 프로세스들이 빠르게 진행되는 것이다.
그럼 본론으로 들어와 파이썬에서 멀티프로세스를 통해 여러 함수들을 실행시켜보자.
from multiprocessing import Process
import time
def print_a():
for i in range(500):
print("Process A!")
time.sleep(0.05)
def print_b():
for i in range(500):
print("Process B!")
time.sleep(0.07)
if __name__ == '__main__':
p_a = Process(target=print_a)
p_b = Process(target=print_b)
count = 0
while True:
count = count + 1
print("count: ", count)
if count == 100000000:
count = 0
if count == 50:
p_a.start()
if count == 70:
p_b.start()
time.sleep(0.1)
p_a.join()
p_b.join()
함수는 "Process A!"를 출력하는 함수와 "Process B!"를 출력하는 함수가 있으며
이들은 무한루프에서 실행된다.
그럼 프로세스는 while을 실행하는 프로세스와 print_a() 함수, print_b() 함수가 실행되게 된다.
하지만 프로젝트 작업을 진행하다보면 현재 프로젝트에서 새로운 기능을 넣거나 실험해보고 싶은 내용이 생길 경우가 있다. 이 경우 원본 파일을 수정하게 되면 다시 원점으로 돌아오기 힘든 상황이 발생할 수 있기에 현재까지는 해당 파일을 다른이름으로 복사하여 작업하고 실험해보는 과정을 진행했었다.
하지만 Git에서는 이러한 과정을 쉽게 다룰 수 있도록 서비스를 제공한다.
Branch가 이러한 내용을 의미한다. 나무에서 가지가 뻗어나가 듯 원본 파일에서 여러 파일들을 뻗어나간다는 의미로 볼 수 있을 것이다.
우선 작업환경을 셋팅하자.
디렉토리를 생성한 후 해당 디렉토리에 기존의 master branch에 대한 내용을 불러오자.
나는 test2라는 폴더를 생성한 후 해당 폴더에 master branch의 내용을 불러왔다.
이제 여기서 Readme.txt파일을 수정한 후 저장하였다.
그리고 추가적은 branch를 생성하기 위해 다음 명령어를 사용하였다.
우선 $ git branch 명령어를 통해 현재 어떠한 branch가 존재하는지 알 수 있다.
처음에는 아무런 branch도 생성하지 않았으므로 master branch만 존재하고 branch 생성을 위해
$ git branch another
위의 명령어를 통해 "another"이라는 이름의 branch를 생성하였다.
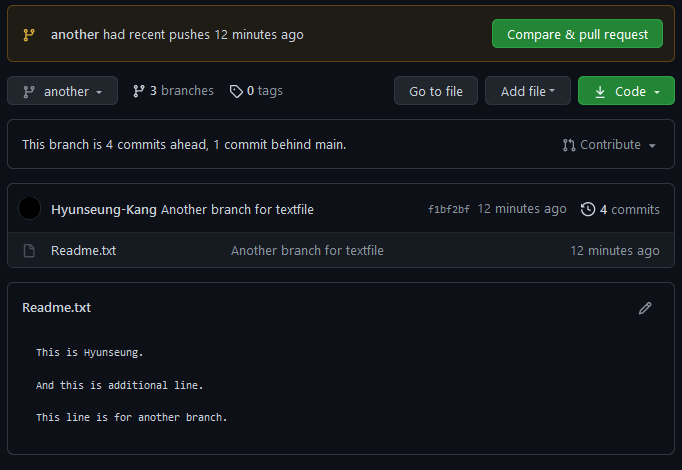
another 이라는 이름의 branch를 생성한 후 제대로 생성되었는지 확인하기 위해
$ git branch 명령어를 다시 입력해보면 위의 그림과 같이 another과 master이 둘 다 출력되고 master에 *표시가 붙은 것을 확인할 수 있다. 즉 현재 master branch 상태의 환경이라는 것이다.
$ git checkout another 명령어를 통해 현재 환경을 another branch로 변경해주자.
그럼 커맨드라인의 끝에 ( master ) 로 표시되던 부분이 ( another ) 로 변경되는 것을 확인할 수 있다.
그럼 깃허브 저장소에 있는 파일을 불러와 수정하고 다시 업로드(push)하는 과정을 진행해보자.
우선 새로운 폴더 test1을 생성한 후 git init을 통해 초기화해준다.
그럼 이제 해당 txt파일을 수정하자.
원래 아무 내용도 없던 텍스트파일에 임의의 문구를 작성한 후 저장하자.
그리고 git status를 확인해보면 다음과 같다.
그럼 이제 변경된 파일을 push하여 깃허브 저장소에 업로드하자.
그럼 이제 다시 깃허브 저장소로 이동하여 확인하여보자.
저장소에서 붉은색으로 표시한 부분을 클릭해보자.
그리고 branch들이 표시되는 부분에 master로 설정하면 초기 저장소에 Readme.txt파일을 생성하여 push했을 때, Edit Readme.txt 라는 커밋메시지의 내용을 push했을 때, 그리고 추가적으로 Secondary Edit on Readme.txt 라는 커밋메시지의 내용을 push하였고 모든 history가 확인되는 것을 볼 수 있다.
그럼 Readme.txt파일은 가장 마지막에 수정한 내용으로 작성되어 있음을 확인할 수 있다.