파일을 읽어오는데 계속 문제가 발생한다.
csv파일이 저장될때의 encoding방식을 알아야 해당 파일을 정확히 읽어올 수 있을 것 같다.

위의 방식으로 해당 파일의 인코딩 방식을 알아보면

위와같이 ascii 형식으로 encoding 되었다고 출력되는데

이렇게 파일의 encoding 방식을 ascii라고 지정해주면

이러한 에러가 출력된다.
아무래도 ascii로 인코딩된게 아닌 것 같다.
해당 파일은 SPR장비의 Punching부분의 센서를 통해 출력되는 데이터고 SPR장비는 독일의 Bollhoff 제품이다.
따라서 독일어의 인코딩방식을 적용하니 잘 출력이 된다.
ko.wikipedia.org/wiki/%EB%AC%B8%EC%9E%90_%EC%9D%B8%EC%BD%94%EB%94%A9
문자 인코딩 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 문자 인코딩영어: character encoding), 줄여서 인코딩은 사용자가 입력한 문자나 기호들을 컴퓨터가 이용할 수 있는 신호로 만드는 것을 말한다. 넓은 의미의 컴퓨
ko.wikipedia.org
위의 링크를 통해 인코딩을 진행하는 문자열 세트의 종류를 확인해볼 수 있다.
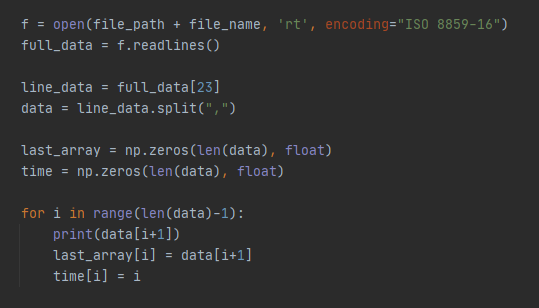
그럼 ISO 8859-16 인 독일어 encoding 방식으로 파일을 열어 데이터를 불러오자.
측정데이터는 , 로 구분되어있으므로 이를 기준으로 나누어 출력해보자.

값들을 잘 저장하다가 중간에 공백이 긴 문자열을 만나면서 ' \x007473.00' 은 float으로 바꿀 수 없다는 에러가 뜬다.

그럼 파일의 해당 라인에 무슨 일이 벌어지고 있길래 저리 긴 공백이 포함되어있고 왜 진행이 안되는지 알아보자.
해당 라인의 데이터를 ,로 구분하여 모두 출력해봤다.


데이터들을 잘 불러오다가 중간중간 위의 에러에서 말한듯이 긴 공백과 함께 \x00 이 붙은 값이 보인다.
이를 해결하기 위해 골머리를 좀 썩혔다.
우선 해당 라인을 , 로 구분하는 것이 아닌 \x00 으로 구분하자.
긴 공백과 함께 \x00 은 데이터라인에 5~6번 등장하므로 이를 기준으로 구분하여 새로운 데이터라인을 만든다.


아까 보였던 \x00 이라는 보기싫은 문자가 보이지 않게 되었다.
이를 기준으로 나누었으므로 이는 기준이 되어 보이지 않고 이를 앞, 뒤로
'DataDataData ', 'DataDataData ','....' 형태로 나뉘게 된다.
그럼 line_data[0] 에는 처음 \x00이 나오기 전까지의 데이터들이 하나의 데이터로 저장되어있고 우리는 원하는 값을 얻기위해 이를 ',' 를 기준으로 나누어줄 필요가 있다.
우선 지금 총 몇개의 데이터로 나누어져있는지 파악하기 위해
위의 코드에서
print(len(data)) 를 사용하여 출력해봤다. 13이라는 출력값을 확인했다.

그럼 반복문을 13번 진행하여 해당 데이터라인을 다시 ' , '로 나누어주자.

그럼 이렇게 \x00 으로 한번 나뉘고 ' , ' 를 기준으로 다시 한번 나눠진 2차원 배열형태가 된다.
그럼 이제 다시 새로운 리스트를 만들어 해당 값들을 모두 한번에 넣어주자.
이 과정도 생각보다 골머리를 썩혔다.
이 방법이 좋은방법은 아닐거같고 더 좋은 방법이 있을 것으로 생각되지만
일단 지금은 생각이 나지 않으므로 지금 생각 난 방법으로 작성하고 향후 더 좋은 방법이 생각나면
개선하도록 하겠다.
우선 배열의 [0][0] 에는 빈칸이 들어있다.
그리고 [1][0] 에는 Value...... 라는 문자열이 들어있고
[1][n], [2][n] 즉 각 배열의 가장 끝 요소에는 공백이 들어가있다.
위의 3가지 경우를 고려하여 유의미한 데이터의 개수를 파악할 수 있다.
그리고 유의미한 데이터들의 위치를 알고있으므로 해당 값들을 가져올수도 있다.
우선 유의미한 데이터들의 개수부터 알아보자.

j와 k 변수를 통해 반복문을 실행하면서 위의 3가지 경우에서는 count를 진행하지않고 넘어가도록 하여
최종적으로 유의미한 데이터의 개수를 count변수에 저장하였다.
그리고 이를 통해 유의미한 데이터들을 담아줄 배열의 크기를 지정해준다.
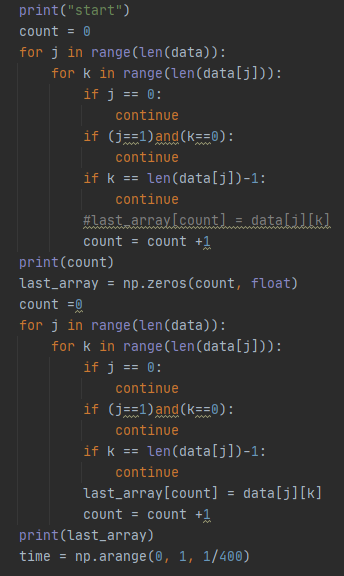
데이터가 담길 크기를 지정해줬으므로 이제 유의미한 데이터들을 넣어주자.
다시 count를 0으로 셋팅해주고 위와 과정을 반복하여 유의미한 데이터를 넣어주자.
잠깐.
앞에서 유의미한 데이터가 담길 배열 크기를 지정해주기 위해 count를 세는 반복문을 진행하였다.
그냥 리스트가 꽉 차면 동적으로 늘려줄 수 는 없는걸까?
좋은 방법을 찾았다.
list에 append함수를 사용하여 값을 추가하여 주는 것이다.
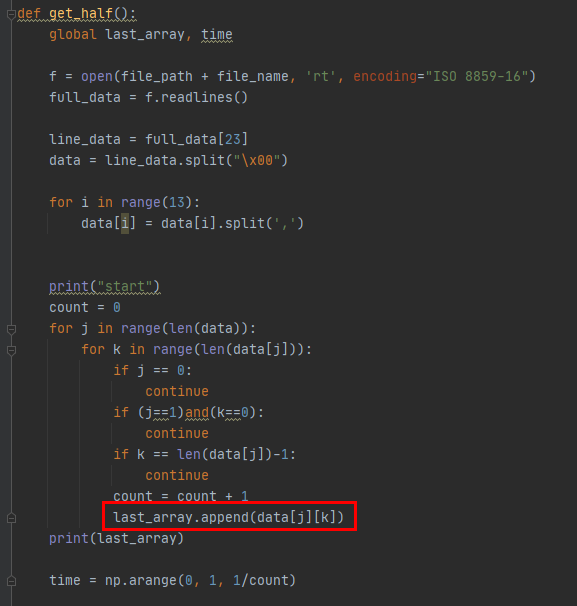

위와 같이 작성하여 last_array를 출력해보면 값은 잘 들어가있는데
그래프로 나타내는 과정에서 문제가 발생한다.
(그래프 그리는 부분을 지우고 해보면 잘 된다.)
원인을 찾아보니 last_array 라는 list에 숫자로 값이 들어간 것이 아닌 문자열로 들어가 이러한 문제가 발생한 듯 싶다.
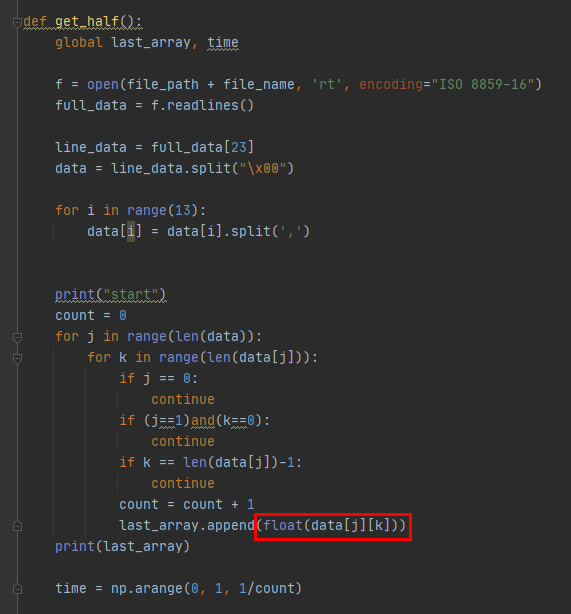
따라서 위와 같이 실행하니 그래프가 잘 출력된다.
이제 값들을 하나의 리스트에 저장하였으니 이들을 이용하여 Feature Data만 추출하면 되겠다.
'Project > CFRP' 카테고리의 다른 글
| _csv.Error: line contains NULL byte (0) | 2020.10.28 |
|---|


